A Practical Guide to Timezones for Developers
If there’s one lesson programming will teach you the hard way, it’s that the world isn’t nearly as neat and orderly as we’d like to believe. I sure thought I knew what a valid email address looks like, or how many names a person has. It’s no wonder that the “Falsehoods Programmers Believe About x” format has become as clichéd as “x Considered Harmful”.
Timezones are one of those tricky subjects, and not just because they’re complicated (they are). When things go wrong with timezones, they usually don’t break in a loud, obvious way; things go subtly wrong, sometimes undetected until long after you’ve deployed to production. Worse still, the problems are often baked into the fundamental design of the program, so correcting the problem isn’t just a simple bug fix.
And while we should absolutely pursue better tooling that can help us avoid logical errors, the most powerful and versatile tool for any programmer is your brain. My intent with this article is to help you build a solid mental model for working with time and timezones.
Let me make one thing clear: this isn’t a problem you can just choose to avoid. If the code you’re writing is going to run on a computer that isn’t yours, then it’s going to be affected by timezones. You’re not simplifying your code by ignoring timezones, you’re sacrificing correctness, and correctness is something we should all strive for.
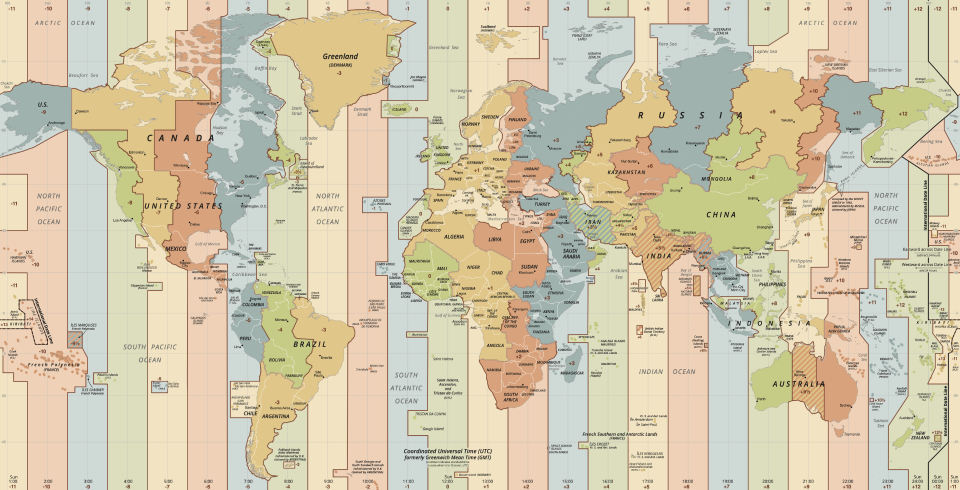
But first, some disclaimers.
The key word in this article’s title is practical, because this isn’t intended to be a comprehensive guide. If you’re writing code that needs to deal with non-Gregorian calendars, or is going to be running on a satellite, go read another article. My goal isn’t to cover every detail or edge case. I’m going to be focusing on the most common situations, admittedly mostly from the perspective of client-server systems. Basically, don’t go into this expecting a discussion of special relativity.
Time is a Line
Time is an illusion. Lunchtime doubly so.
Before digging in to the gory details of timezones, I want to step back and talk about the concept of time itself. While it may seem a bit mundane of a subject, the way we tend to conceptualize time in day-to-day life isn’t conducive to building robust software. You don’t need to rewire your brain to git gud at timezones, but a good abstraction can go a long way.
Time is like a continuous line with no beginning or end. If you pick some arbitrary point on the line, you would have a single, instantaneous point in time. We’ll call that an instant, and it’s the fundamental unit of time in this abstraction.
Because our timeline has no beginning or end, we can’t measure anything absolutely, but we can measure relatively. If you have two instants, you can determine the amount of time that has elapsed between them, measured to some precision (say, to the nearest millisecond); that’s a duration. You can also add or subtract a duration from an instant to get a different instant (i.e. “five minutes ago”).
If you modeled this in a programming language, it’d look something like this:
Instant - Instant -> Duration
Instant ± Duration -> Instant
How might a system actually represent an instant as data? While we can’t absolutely measure instants, we can pick an arbitrary point and measure relative to that— that’s basically how all date systems work. There’s a simple, widely used, and most importantly, standardized system we can use: Coordinated Universal Time, abbreviated as UTC. It’s the timekeeping system that the world basically runs on, and as far as this article is concerned, we can treat it as the canonical representation of an instant.
To make working with UTC dates less cumbersome for computers, lots of software uses a simpler instant representation: Unix time. It represents an instant as simply the number of seconds since midnight on January 1st, 1970 in UTC (ignoring leap seconds). This lets you store an instant as a simple numeric type, and you can use basic arithmetic to implement duration operations, making Unix time a popular choice.
There’s one more important tool your computer has for working with time, and that’s the concept of “now.” Almost every computer has a system clock which, in theory, is synchronized with everyone else’s system clocks and lets you spit out some representation of the current instant. In practice, the system clock will be out of sync by some small amount, and can be out by a quite large amount, so your computer’s “now” might be in the past/future for everyone else.
There’s no magic bullet to deal with that, it’s just something you need to keep in mind whenever you’re passing times between systems. Bummer.
Wall-Clock Time
The point of the “instant” concept is that it gives us a way to think about time objectively, but that’s not how most people actually tell time on a day-to-day basis. Our normal timekeeping systems are based on the sun, and therefore are relative to where you are in the world, making them comparatively subjective. That is to say, clocks in different parts of the world will give different readings, even when they’re both set correctly. We’ll refer to this concept as wall-clock time.
“Instant” time and “wall-clock” time are fundamentally different concepts, and mixing them up is a common source of timezone bugs. You cannot safely convert wall-clock time to an instant (or vice versa) because the operation is ambiguous without more context. To be able to do that, you need to know the details of the clock that took the measurement, and that’s where timezones come in.
For a while, everyone in the world set their own clocks based on their observations of the sun. Later, 19th century industrialization drove standardization, and the idea of standard time was born.
A timezone is a geopolitical region (hence “zone”) where everyone has agreed that their clocks should be set to the same time. While their geographical boundaries are vaguely based on longitude, the exact borders tend to follow political lines for convenience (e.g. all of China has the same timezone). Timezones are always defined as being ahead or behind UTC by a certain amount of time, which is called a UTC offset. UTC offsets are generally written as UTC±00:00 or UTC±0000.
There’s also the unfortunate practice of daylight savings time to contend with, which is not consistent across the entire timezone. Most of the world doesn’t follow DST, but those that do all use different dates for when to move the clocks forwards or back. And yes, this does pretty much ruin the uniformity of timezones.
Here’s an example: the Eastern Timezone (ET) is a geographical region that follows Eastern Standard Time (EST), which is five hours behind UTC (UTC-5:00). In the spring and summer, some places in the timezone change over to Eastern Daylight Time (EDT), which is only four hours behind UTC (UTC-4:00). Remember: “Eastern Time” is not the same as “Eastern Standard Time.”
Normally you can’t convert wall-clock time to an instant, but if you have the clock’s exact UTC offset, you can safely make the conversion. You can also run that same process in reverse to localize an instant, which is good because users will generally expect things to be displayed in their time. All we need is a UTC offset, but a clock’s offset can change throughout the year, like during DST. If we want more stability, then we need more data.
If we know the clock’s timezone, plus any extra rules like daylight savings time, then we can take a date and work out what UTC offset the clock should have had. From there, we can make the correct conversions.
Instant.applyOffset(UTCOffset) -> WallClockTime
WallClockTime.removeOffset(UTCOffset) -> Instant
Instant.localize(Timezone) -> WallClockTime
WallClockTime.unlocalize(Timezone) -> Instant
So, all our program needs is a record of all timezones and their rules. How complicated could that be?
The IANA Timezone Database
Very complicated, as it turns out.
Timezones change. Frequently. Generally it’s not the rules themselves that change (it’s unlikely that EST will ever not be UTC-5:00), but instead governments changing which timezones they follow. Not to mention daylight savings time rules, which governments tweak all the time.
ICANN has taken on the extremely unenviable task of building and maintaining a (reasonably) comprehensive history of timezone changes, which is one of those things that you really don’t want to do. The result is the IANA timezone database, also sometimes called the tz database. Most computers already have a copy of it, and it is your best friend for working with timezones.
You can easily download a copy of the database. The format is plain-text-based, so it’s easy to poke around. But start looking for, say, an entry for the Eastern Timezone and you won’t find much. US/Eastern in defined a file called backward, but it’s actually just aliased to America/New_York. theory.html provides some more context here:
Older versions of this package used a different naming scheme. See the file '
backward' for most of these older names (e.g., 'US/Eastern' instead of 'America/New_York').
Why’s that? Let’s look in northamerica for some more context. Here’s the definition for America/New_York:
# NAME STDOFF RULES FORMAT [UNTIL]
Zone America/New_York -4:56:02 - LMT 1883 Nov 18 17:00u
-5:00 US E%sT 1920
-5:00 NYC E%sT 1942
-5:00 US E%sT 1946
-5:00 NYC E%sT 1967
-5:00 US E%sT
The STDOFF column specifies the base UTC offset of the timezone. RULES is a little more complicated, but it’s basically how the database handles daylight savings time (these are defined elsewhere in the file). So, from this entry we can see that the UTC-5:00 offset was brought into effect in 1883— checks out. From there, the rules for daylight savings time shifted around until that was standardized in 1967.
Good to know. Another file lets us know why New York in particular was chosen:
Timezones are typically identified by continent or ocean and then by the name of the largest city within the region containing the clocks.
However, to really understand the motivation behind this design, we need to look at Indiana. Oh, Indiana…
So, Indiana was originally officially placed in Central Time, but a lot of people in the state were very unhappy about this. Over a literal century of political bickering, the state has been painstakingly slowly transitioning over to Eastern Time— a process that is still incomplete and will almost certainly continue into the future. And this is before getting into the perpetual back-and-forth across the state over daylight savings time.
Shanks partitioned Indiana into 345 regions, each with its own time history, and wrote "Even newspaper reports present contradictory information." Those Hoosiers! Such a flighty and changeable people! Fortunately, most of the complexity occurred before our cutoff date of 1970.
The IANA maintainers have decided the situation is so dire that they’ve given Indiana its own America/Indiana namespace to contain the mess. Wikipedia says that there are eleven different IANA timezones used in Indiana. Here’s one:
# NAME STDOFF RULES FORMAT [UNTIL]
Zone America/Indiana/Indianapolis -5:44:38 - LMT 1883 Nov 18 18:00u
-6:00 US C%sT 1920
-6:00 Indianapolis C%sT 1942
-6:00 US C%sT 1946
-6:00 Indianapolis C%sT 1955 Apr 24 2:00
-5:00 - EST 1957 Sep 29 2:00
-6:00 - CST 1958 Apr 27 2:00
-5:00 - EST 1969
-5:00 US E%sT 1971
-5:00 - EST 2006
-5:00 US E%sT
The difference between this timezone and America/New_York should be obvious, even though they both end up in the same place by the end. You can see the UTC offset flipping back and forth between UTC-6:00 and UTC-5:00, not to mention the repeated fiddling with daylight savings time.
This is why the IANA Timezone Database won’t just give you an “Eastern” timezone, and what makes it so powerful. While Indianapolis and New York are in the same timezone right now, they have very different histories. That historical context is necessary to make correct calculations for moments in the past. With it, you can, in theory, take any instant and figure out the equivalent wall-clock time anywhere in the world. Or, you can run the process in reverse: take a wall-clock measurement and, if you know its timezone, find the instant that measurement was taken. At least for dates after 1970— before that, the data is fuzzier, but usually good enough.
Note the “in theory” qualifier, because there are some big edge cases to worry about. Whenever the local clocks are adjusted for daylight savings time or timezone changes, there will be either gaps or repeats in the local wall-clock time. A gap means some timestamps never happened and are invalid; a repeat means one wall-clock timestamp could refer to two instants.
There will always be some ambiguity when doing timezone conversions, but at least it’s manageable. You should treat these conversions as a potentially lossy operation, and generally try to perform as few as necessary.
Designing Systems
If you’ve understood everything you’ve read up to this point, then you should be armed with the theoretical tools you need to write correct timezone-aware software. In this final section, I’d like to get into how to apply these concepts.
First things first, you need to understand how your language, framework, or date library of choice represents time. Go check the docs, because every language handles it differently, and appearances can be deceiving. Take JavaScript for example:
console.log(new Date())
'Tue Jan 31 2023 16:30:42 GMT-0500 (Eastern Standard Time)'It sure looks like wall clock time, and that’s because it is— when it gets printed as a string. In JavaScript, Date objects are actually instants, and are represented in-memory as a Unix timestamp. But whenever you actually display one, it just uses your computer’s configured timezone to localize it (the upcoming Temporal API should be much clearer).
Understanding and deciding when to use instants and when to use wall-clock time is one of the most important calls you’ll have to make. In some cases, the answer should be obvious: if you need to store when something was created, that’s clearly an instant, because it’s an objective point in time. In my experience, instants are definitely more common in backend systems, especially for anything that happened in the past. But there will be other times when the answer isn’t clear, and you’ll have to make a design decision.
Say a user schedules an event for July 1st at 10:00, but the country that user is located in later decides to stop observing daylight savings time. How should the program react? If we store the date as an instant, then the localized representation of the date now becomes July 1st, 9:00. If we store wall clock time with a timezone, then the localized date remains the same, but the event is now an hour farther from when it was scheduled. There’s no right answer here, both designs are potentially valid. It’s the difference between “remind me in an hour” and “remind me at 8:00.”
Regardless of how your backend operates, in most applications users will expect to see dates in their local timezone. In a client-server architecture, you have two options. The first, and my general preference, is to send an instant and localize it on the client using the user’s system timezone. I like using UTC with the ISO 8601 format: it’s human-readable and obviously represents a date. The alternative approach is to localize dates on the server, using timezone data either included by the client in requests or stored server-side in the user’s preferences.
You can do the same thing when the user is submitting dates, too. Since the client probably knows the user’s timezone, the user can enter a localized date and you can convert it to UTC internally before submitting or storing it. Of course, you probably only want to do that if your backend representation is an instant. Otherwise, you should just use the localized value and have the client also include the user’s timezone.
One thing to watch out for is “plain dates”, meaning dates without an attached time. I’ve found that plain dates are easy to mangle, because they don’t really represent a single point in time; plain dates are more like a 24-hour range (usually, thanks DST). So what you really have is two dates forming the bounds, and you need to handle them in a timezone-aware way. Remember: there are always two different “today”s in the world.
Finally, we have to talk about the least-fun part of any software project: the business logic. Business logic that depends on wall-clock time can be a big source of headaches, and bugs if you’re not careful.
If you have the choice, the easiest way to deal with the problem is to simply circumvent it by redefining the requirements to avoid wall-clock time. “Every 24 hours” is much easier than “every morning at 9:00 AM.” Running the business logic on UTC is another good choice, if you can get away with it, since it eliminates time changes like daylight savings time.
But, in many cases, the business logic is non-negotiable, and you’re going to have to deal with wall-clock time. Best case scenario, the business logic just runs on a single timezone; the rule becomes “every morning at 9:00 AM, Eastern Time,” and you store America/New_York as a constant somewhere. This still has a lot of ways it can get complicated: daylight savings time needs to be considered, the timezone specified in the requirements could change, or the rules of the timezone itself could change. You should have a plan in place to deal with these eventualities.
For anything more complex, I can’t really give general advice. You’re going to need to forge your own path. Whatever you do, just make sure you are explicit about what timezone(s) your business logic is using, and document it well.
Final Thoughts
I wish the world were simpler, but alas, it’s not.
Timezones are something I’ve definitely struggled with, and still do sometimes. I don’t claim to be an expert, but I also don’t think you have to be to build working, correct software. You can go much deeper than I have here, but hopefully you’ll never need to.